 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCesarean Scar Defect Segmentation in Transvaginal Ultrasound Images: a Dataset and Benchmark
May 26, 2026Cesarean Scar Defect (CSD) is one of the most prevalent complications following cesarean delivery. Transvaginal ultrasonography is widely used for primary CSD screening. Accurate determination of CSD outline and dimensions is crucial for treatment. However, CSDs are frequently overlooked by sonographers due to small size and irregular morphology, suboptimal image quality, and limited clinical awareness in resource-constrained settings. Despite artificial intelligence advances in medical imaging, no public dataset exists for transvaginal ultrasound CSD segmentation. To address this gap, we present a comprehensive CSD dataset comprising 1,111 images and 16 videos, yielding 501 positive samples with confirmed CSD and precise pixel-level manual annotations. Annotations are performed following standardized clinical guidelines through collaboration between experienced sonographers and trained PhD students. This work provides high-quality benchmark resources for advancing medical image segmentation algorithms and promoting clinical innovation. Ultimately, improved CSD diagnosis and subsequent treatment strategies can enhance the quality of life in women of reproductive age, representing significant value for both medical research and clinical practice.
MoXaRt: Audio-Visual Object-Guided Sound Interaction for XR
Mar 11, 2026In Extended Reality (XR), complex acoustic environments often overwhelm users, compromising both scene awareness and social engagement due to entangled sound sources. We introduce MoXaRt, a real-time XR system that uses audio-visual cues to separate these sources and enable fine-grained sound interaction. MoXaRt's core is a cascaded architecture that performs coarse, audio-only separation in parallel with visual detection of sources (e.g., faces, instruments). These visual anchors then guide refinement networks to isolate individual sources, separating complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with ~2 second processing latency. We validate MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study. Empirical results indicate that our system significantly enhances speech intelligibility, yielding a 36.2% (p < 0.01) increase in listening comprehension within adversarial acoustic environments while substantially reducing cognitive load (p < 0.001), thereby paving the way for more perceptive and socially adept XR experiences.
SPAN-Nav: Generalized Spatial Awareness for Versatile Vision-Language Navigation
Mar 10, 2026Recent embodied navigation approaches leveraging Vision-Language Models (VLMs) demonstrate strong generalization in versatile Vision-Language Navigation (VLN). However, reliable path planning in complex environments remains challenging due to insufficient spatial awareness. In this work, we introduce SPAN-Nav, an end-to-end foundation model designed to infuse embodied navigation with universal 3D spatial awareness using RGB video streams. SPAN-Nav extracts spatial priors across diverse scenes through an occupancy prediction task on extensive indoor and outdoor environments. To mitigate the computational burden, we introduce a compact representation for spatial priors, finding that a single token is sufficient to encapsulate the coarse-grained cues essential for navigation tasks. Furthermore, inspired by the Chain-of-Thought (CoT) mechanism, SPAN-Nav utilizes this single spatial token to explicitly inject spatial cues into action reasoning through an end-to end framework. Leveraging multi-task co-training, SPAN-Nav captures task-adaptive cues from generalized spatial priors, enabling robust spatial awareness to generalize even to the task lacking explicit spatial supervision. To support comprehensive spatial learning, we present a massive dataset of 4.2 million occupancy annotations that covers both indoor and outdoor scenes across multi-type navigation tasks. SPAN-Nav achieves state-of-the-art performance across three benchmarks spanning diverse scenarios and varied navigation tasks. Finally, real-world experiments validate the robust generalization and practical reliability of our approach across complex physical scenarios.
Generative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
Enhancing XR Auditory Realism via Multimodal Scene-Aware Acoustic Rendering
Nov 14, 2025



In Extended Reality (XR), rendering sound that accurately simulates real-world acoustics is pivotal in creating lifelike and believable virtual experiences. However, existing XR spatial audio rendering methods often struggle with real-time adaptation to diverse physical scenes, causing a sensory mismatch between visual and auditory cues that disrupts user immersion. To address this, we introduce SAMOSA, a novel on-device system that renders spatially accurate sound by dynamically adapting to its physical environment. SAMOSA leverages a synergistic multimodal scene representation by fusing real-time estimations of room geometry, surface materials, and semantic-driven acoustic context. This rich representation then enables efficient acoustic calibration via scene priors, allowing the system to synthesize a highly realistic Room Impulse Response (RIR). We validate our system through technical evaluation using acoustic metrics for RIR synthesis across various room configurations and sound types, alongside an expert evaluation (N=12). Evaluation results demonstrate SAMOSA's feasibility and efficacy in enhancing XR auditory realism.
Steerable Chatbots: Personalizing LLMs with Preference-Based Activation Steering
May 07, 2025



As large language models (LLMs) improve in their capacity to serve as personal AI assistants, their ability to output uniquely tailored, personalized responses that align with the soft preferences of their users is essential for enhancing user satisfaction and retention. However, untrained lay users have poor prompt specification abilities and often struggle with conveying their latent preferences to AI assistants. To address this, we leverage activation steering to guide LLMs to align with interpretable preference dimensions during inference. In contrast to memory-based personalization methods that require longer user history, steering is extremely lightweight and can be easily controlled by the user via an linear strength factor. We embed steering into three different interactive chatbot interfaces and conduct a within-subjects user study (n=14) to investigate how end users prefer to personalize their conversations. The results demonstrate the effectiveness of preference-based steering for aligning real-world conversations with hidden user preferences, and highlight further insights on how diverse values around control, usability, and transparency lead users to prefer different interfaces.
AcL: Action Learner for Fault-Tolerant Quadruped Locomotion Control
Mar 27, 2025



Quadrupedal robots can learn versatile locomotion skills but remain vulnerable when one or more joints lose power. In contrast, dogs and cats can adopt limping gaits when injured, demonstrating their remarkable ability to adapt to physical conditions. Inspired by such adaptability, this paper presents Action Learner (AcL), a novel teacher-student reinforcement learning framework that enables quadrupeds to autonomously adapt their gait for stable walking under multiple joint faults. Unlike conventional teacher-student approaches that enforce strict imitation, AcL leverages teacher policies to generate style rewards, guiding the student policy without requiring precise replication. We train multiple teacher policies, each corresponding to a different fault condition, and subsequently distill them into a single student policy with an encoder-decoder architecture. While prior works primarily address single-joint faults, AcL enables quadrupeds to walk with up to four faulty joints across one or two legs, autonomously switching between different limping gaits when faults occur. We validate AcL on a real Go2 quadruped robot under single- and double-joint faults, demonstrating fault-tolerant, stable walking, smooth gait transitions between normal and lamb gaits, and robustness against external disturbances.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
ELSR: Extreme Low-Power Super Resolution Network For Mobile Devices
Aug 31, 2022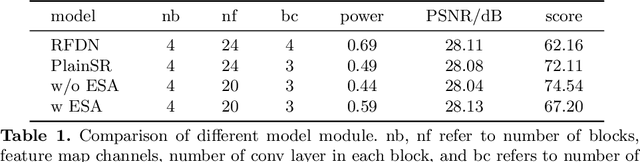
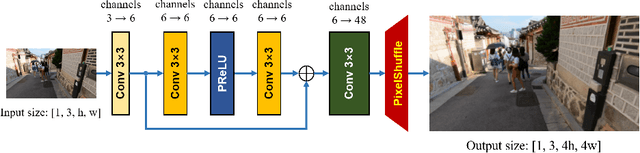

With the popularity of mobile devices, e.g., smartphone and wearable devices, lighter and faster model is crucial for the application of video super resolution. However, most previous lightweight models tend to concentrate on reducing lantency of model inference on desktop GPU, which may be not energy efficient in current mobile devices. In this paper, we proposed Extreme Low-Power Super Resolution (ELSR) network which only consumes a small amount of energy in mobile devices. Pretraining and finetuning methods are applied to boost the performance of the extremely tiny model. Extensive experiments show that our method achieves a excellent balance between restoration quality and power consumption. Finally, we achieve a competitive score of 90.9 with PSNR 27.34 dB and power 0.09 W/30FPS on the target MediaTek Dimensity 9000 plantform, ranking 1st place in the Mobile AI & AIM 2022 Real-Time Video Super-Resolution Challenge.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022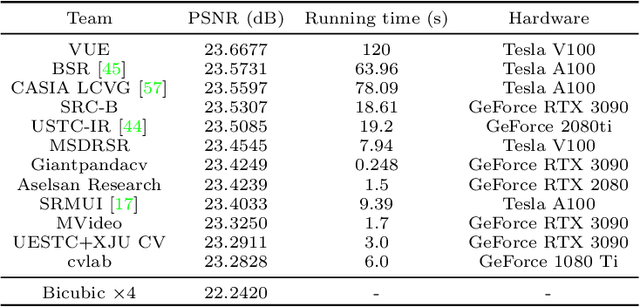
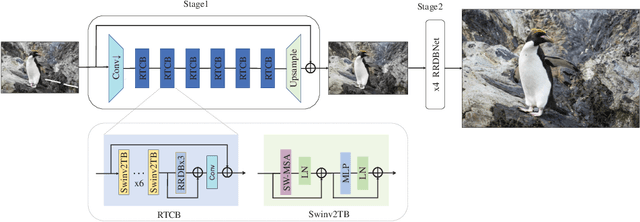

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.